

엔지니어 블로그
[Spark] Spark Architecture 본문
1. Spark의 기본적인 아키텍처

Spark은 기본적으로 3 부분으로 나누어 볼 수 있다.
1.Driver
2.Cluster Manager
3.Executor
1.Driver
Dirver는 Spark Application을 실행하는 역할이다. main 함수를 실행하고 SparkContext 객체를 생성하게 된다.
2.Cluster Manager
Driver로 부터 실행계획을 전달 받아 필요한 만큼의 Worker를 생성하게 된다. YARN,K8S가 사용되며 Worker의 failover도 담당하게 된다.
3. Executor
다수의 Worker 노드에서 실행되는 프로세스로 Spark Driver가 할당한 작업을 수행하여 결과를 반환한다.
2. Spark 작동 과정
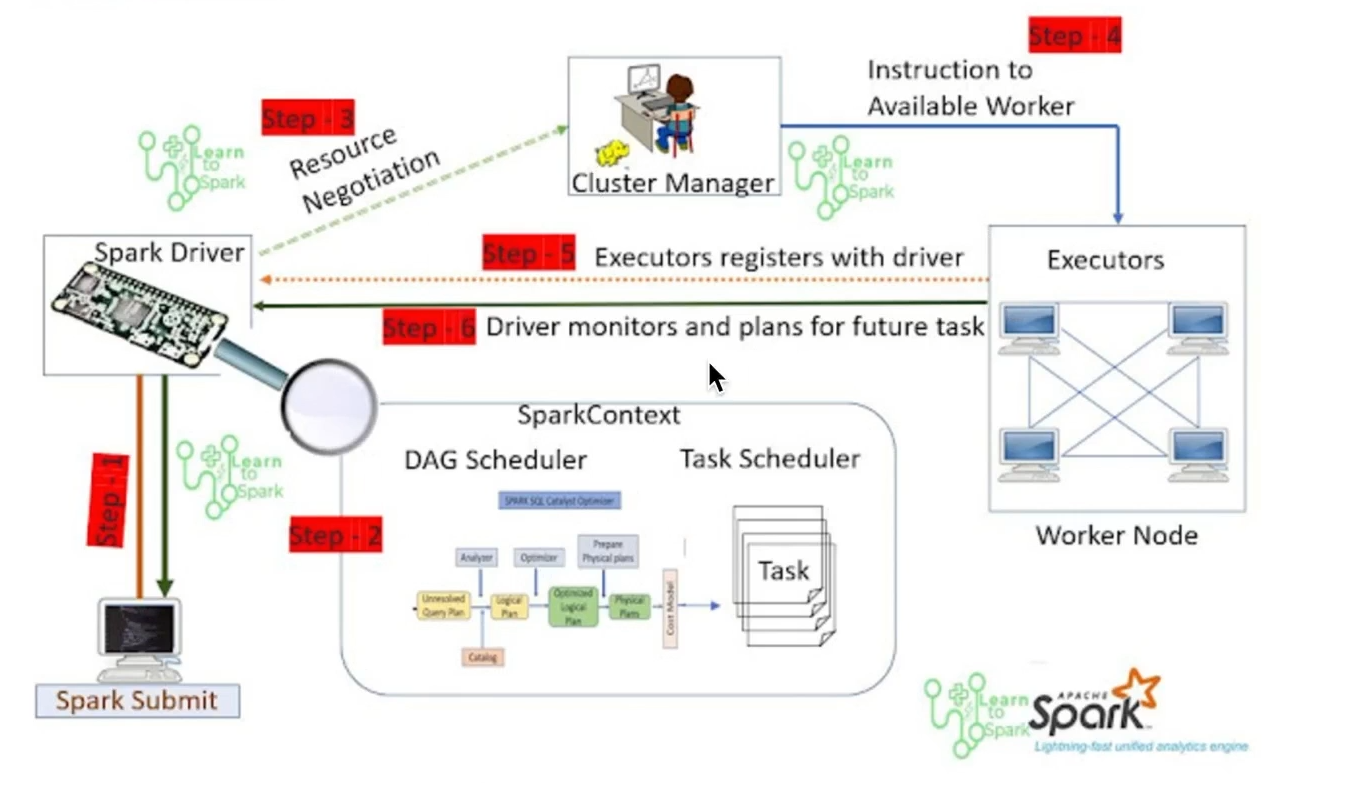
1.Spark Sumit
Driver에게 작업 내용 전달
2.Spark Context 생성
DAG Scheduler,Task Scheduler 를 통해 작업 실행 계획 수립
이때 필요 Executor 수 등을 정함
3.Cluster Manager에게 실행계획 전달
실행계획을 전달하여 Cluster Manager가 몇개의 Node를 생성해야 할지 결정
4.Woker Node 생성
Worker Node를 생성하여 필요 Executor를 확보한다.
5.Executor 상태 및 결과 전달
Dirver에게 Executor의 상태 및 작업 결과를 전달한다.
6.Client에게 결과 전달
Driver가 Executor로부터 전달받은 결과를 Client에게 전달한다
'Spark' 카테고리의 다른 글
| [Spark] Lazy Evaluation (0) | 2025.04.06 |
|---|---|
| [Spark] Partition (0) | 2025.03.26 |
| [Spark] Spark 기본 동작 (0) | 2025.03.25 |
| Parquet란? (0) | 2025.03.21 |
| [Spark] Spark 개요 (0) | 2025.02.25 |
'Spark' Related Articles
more


